When reading non-trading related books I always like to think about how they might apply to my field of choice. One of my all-time favorite books is one which at first glance has nothing to do with markets. In Extreme Ownership: How U.S. Navy SEALs Lead and Win1 authors and retired Navy SEAL officers Jocko Willink and Leif Babin take us through the leadership lessons they learned through the treacherous streets of Ramadi (Iraq) during some of the heaviest fighting of that conflict. With some interpretation many of the principles in the book can be very useful to traders. Here is some of the lessons I learned in my career that can be tied in with those principles.
Ch1: Extreme ownership
One must own everything in his world. Taking responsibility for everything impacting the objective before the fact and also taking responsibility for the outcome good or bad is in essence what this whole book is about.
In the trading world one can easily see how this is applicable. Only by taking full ownership of every part of the process can one be successful in the markets. In practice that means understanding and taking responsibility for every step of the process. The research, the execution, the post-trade analysis the risk management, everything. Finally, by being ruthless when assessing performance and not making excuses for bad results, one can objectively asses the situation and take appropriate actions.
Ch2: No bad teams, only bad leaders
If a team performs poorly, the responsibility lies squarely on the leader. By setting the standard and most importantly enforcing it, the leader can create a culture of success.
This really resonated with me regarding my days as a the senior trader on a desk. Working as a team all working towards the same goal it was really important to set a clear standard for everybody to follow. I found this particularly important for on boarding new team members or interns. By clearly defining the expectations it removed a tremendous amount of pressure from them to “do the right thing”. They seldom had to worry about that since the right thing to do had already been outlined for them. This allowed them to gain confidence early on which let them focus on being successful members of the team.
Ch3: Believe
In order to convince and inspire others to follow and accomplish a mission, a leader must be a *true believer* in the mission.
The situation which resonate the most with this principle for me is when a team member comes up with a strategy who he thinks would be worth going live with. The way this usually works in my experience is that the senior trader would take it on as part of his platform and eat the loss if the strategy doesn’t work as expected for whatever reason. In order for this process to work, the senior trader must really believe in what is being attempted. Failure to do that will only serve to stifle the process and embitter the creator of the strategy. It is then very important to commit to the idea and to believe it can be successful in order to make the development process work.
Ch4: Check the ego
Implementing extreme ownership requires checking your ego and operating with a high degree of humility.
Anybody having traded for long enough will know that there are only two ways to learn humility in trading; on your own, or alternatively and much more painfully, by having the market do it. As you can imagine the latter is quite costly at times. One only has to look at all the providers of “volatility strategies” subscription services in February to see a prime example of that. Only by ruthlessly admitting mistake, considering risks and weaknesses can one develop a good plan to succeed.
Ch5: Cover and move
This is about having every element of the process supporting one another.
In the trading sphere this is makes the case for diversification. This does not need much explanation for you dear reader as I know you are all very familiar with that concept. A collection of individually uncorrelated return streams is the only true “Holy Grail” I know of in the trading world. On the employee management side it also means that each member of the team must cover for one another. Trying to stand out individually by putting oneself before the good of the team is a very good way to ensure sub-optimal results. A senior trader must make that fact clear to everyone and tolerate no violations of any kind on that front.
Ch6: Simple
Simplifying as much as possible is crucial to success.
When things go wrong and as you all know, they will go wrong, complexity compounds issues that can spiral out of control into catastrophic losses. In addition to that, think in term of degrees of freedom or number of parameters in a model. Many dollars of mine have been lit on fire over the years to over-fitting even after what I would say were reasonably good precautions to avoid it. While of the other hand the best results and what made me the most money is the thoughtful application of simple techniques that I understood well.
Ch7: Prioritize and execute.
The way to handle countless complex problems snowballing is by prioritizing tasks and executing them focusing all your attention on the highest priority task. “Relax, look around, make a call.”
From a time management perspective this is quite important. There is only so many hours in a day and if you are anything like me your to-do list is endless and ever-growing. From research, strategy implementation, trade monitoring, post-trade analysis, risk monitoring and everything in between the only way to make an effective dent in said to-do list and improve your platform is to aggressively prioritize each task and tackle them successively focusing on the highest priority one. It is also important to recognize that those priorities are shifting in real-time. For instance, focusing on research while a production algo loses connectivity would be a problem to say the least! Additionally, in a risk limit liquidation, affectionately known as a puke situation where say multiple algorithms are requiring immediate action all at the same time this becomes a matter of survival for a trading platform. If the liquidation isn’t handled in a disciplined and unemotional fashion it can lead to much larger losses so prioritization here again is key.
Ch8: Decentralized command
Team members must be aware of the intent and be empowered to make decisions that are in line with that intent within well-defined limits to their decision-making abilities.
For instance, running a desk that operates during all major market sessions (Asia, Europe, America) it is impossible for a senior trader to always manage all the minute details. In addition to that, traders responsible for the desk during those sessions must know what they are trying to accomplish and what they can and also importantly cannot do in other to reach that goal. It is no use having somebody sitting in front of a computer overnight without any power to make any real decisions. All that ends up creating is a lot of lost sleep over middle of the night phone conversations. Furthermore, many such situations are time-sensitive. One can’t afford to have the execution trader not empowered to make decisions once they are needed. That being said, it is critical to clearly outline what are the limits of that decision-making authority. This is one of the areas where I really struggle because it is often very difficult to own the result of something that you don’t end up directly causing. But the important part here is that it is one job to mentor and train those people so that there is no scenarios where they would make a decision that goes against the intent which in our case is always to make the most money possible while minimizing the associated risk.
Ch9: Plan
Each course of action must be carefully planned. When doing so, it is important to account for likely contingencies and mitigate risk that can be controlled as much as possible. Finally, circle back and evaluate how successful the plan to implement lessons learned in future plans.
I know many of my readers are also listener of the excellent Chat with Traders podcast. Those will be very familiar with this recurring theme with many of the guests. Having a plan before stepping into the ring is a good way to improve the range of outcomes you will experience. When money is on the line, emotions get involved and having a solid plan on top of having already evaluated contingencies allows one to be a lot better at handling various scenarios. By being explicit about the plan, one also ensures that they can create a feedback look of success where the lesson learned are applied to future plans leveraging everyone’s experience.
Ch10: Leading up and down the chain of command
One must take ownership of the relationship with subordinate and superiors and make sure that everyone has all the information that they need to be effective in their respective jobs.
The importance of leading down the chain as a senior trader is obvious. Specifically, the traders executing the strategies need to have all the information they need to be effective. What might be less obvious is how one would manage their relationship to their superior. The idea here is that in the prop world capital is limited. As such in order to be allocated capital the partners need to have certain information. In order to be an effective senior trader, one must proactively provide that information and also periodically updating management on the process of various projects. That way, I have found that it is much easier to get buy-in for new ventures and build confidence so that over time, more leeway is available. An interesting dichotomy here is that by enabling your superiors to do their job more easily a senior trader will be more successful.
Ch11: Decisiveness amid uncertainty
Amid the pressure from uncertainty, chaos and the element of unknown that one must contend with, it is critical for leaders to act decisively; make the best decisions possible based on only the immediate information available.
Markets are inherently stochastic; it is usually impossible to have enough information to be certain which course of action is best. That said being indecisive is rarely the right decision. In my experience it is often better to decisively commit and make a decision that turns out to be wrong after the fact rather than wait in perpetuum for more information. By being decisive and using some prioritization even wrong decision become easier to handle and the resulting outcome is often better than the alternative on undecisive actions or worst inaction.
Ch12: Discipline equals freedom
Maintaining a high degree of discipline allows the freedom necessary to be successful.
Long term readers of this blog will know that I am not the most educated, most intelligent, or most talented trader around; far from it. The only reason I was able to have some success in my trading endeavors is my discipline. As the authors put it, “unmitigated daily discipline in all things” is truly the only edge that I have over my competitors. Many might think that having a high degree of self-discipline is coercive more than anything. That, in my experience, could not be further from the truth. Only by being disciplined can I have the freedom to do what is necessary to obtain success. Additionally, it should come as good news to every one of my readers that are considering putting some of their capital at risk since discipline is something you can start working on at any time. This is not a nature vs nurture situation; it is pure force of will. Anyone can reach the level of discipline I believe is required in order to be a successful trader.
To wrap things up, I cannot recommend the book enough. It is a good read if you are interested in becoming a better person, let alone trader. I also should mention that I don’t pretend to have all the answers. I have failed many more times than I have been successful but by constantly seeking thoughtful failure, I was able to find fantastic success. Something I think that is within reach for just about everyone with the required discipline and proper effort.
1. Willink, Jocko., and Leif Babin. Extreme Ownership: How U.S. Navy SEALs Lead and Win. First edition. St. Martin’s Press, 2015.↩


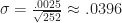


 In addition the trading state, the following states would be defined as well as they are relevant to the strategy:
In addition the trading state, the following states would be defined as well as they are relevant to the strategy:  and finally
and finally  . That is to say then that the state space of our algorithm is defined by the following triplet
. That is to say then that the state space of our algorithm is defined by the following triplet 



 . The transitions in this case will have to do with the reception of exchange order events such as acknowledgement, reject messages etc. If you stop to think about it, you could design a whole trading stack with almost nothing but FSMs. By using FSMs you can design to insure correctness of your algorithms and eliminate a whole class of potential design flaws that might sneak in otherwise.
. The transitions in this case will have to do with the reception of exchange order events such as acknowledgement, reject messages etc. If you stop to think about it, you could design a whole trading stack with almost nothing but FSMs. By using FSMs you can design to insure correctness of your algorithms and eliminate a whole class of potential design flaws that might sneak in otherwise.